神经网络的学习
从数据中学习
所谓的学习就是从训练数据中自动获取最优权重参数的过程
为了使神经网络能够学习,引入了损失函数这一指标,而学习的目标就是以损失函数为基准,找出使它的值达到最小的权重参数(函数斜率的梯度法)
特征量:是指可以从输入数据(输入图像)中准确地提取出本质数据(重要数据)的转换器(图像的特征量通常表示为向量形式),但特征量的选取是人为选择的,还是存在人为因素的介入
深度学习也被称为端到端机器学习(end-to-end machine learning),从原始数据(输入)中获得目标结果(输出)
神经网络的优点是对所有的问题都可以使用同样的流程来解决,与待处理的问题无关,它可以将数据直接作为原始数据,进行端到端学习
在机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验,首先使用训练数据进行学习,寻找最优参数,再使用测试数据评价训练得到的模型的实际能力
划分为训练数据和测试数据(也称为监督数据)是为了追求“泛化能力”
泛化能力:是指处理未被观察过的数据(不包含在训练数据中的数据)的能力
获得泛化能力是机器学习的最终目标
过拟合:它是指只对某个数据集过度拟合的状态
损失函数
神经网络的学习通过某个指标表示现在的状态,再以这个指标为基准,寻找最优权重参数,而这个指标就是损失函数
损失函数可以使用任何函数,但一般使用的是均方误差和交叉熵误差
损失函数是表示神经网络性能好坏的指标,它反映了当前的神经网络对监督数据的拟合程度
均方误差
其表达式如下:
$$
E = \frac{1}{2} \sum_{k} (y_k - t_k)^2
$$其中,$y_k$ 是表示神经网络的输出,$t_k$ 表示监督数据(测试数据),$k$ 表示数据的维数
题外话:均方误差式子的一个特点就是,其名中的4个字与式子中皆有对应,均 对应式子中的 $\frac{1}{2}$ ,方 对应式子中的 $()^2$ ,误差 对应式子中的 $ y_k - t_k $
交叉熵误差
其表达式如下:
$$
E = - \sum_{k} t_k \log y_k
$$其中,$y_k$ 是表示神经网络的输出,$t_k$ 是正确解标签,且 $t_k$ 中只有正确解标签的索引为1,其余的都是0(one-hot表示)
所以说,实际上交叉熵误差式子只计算对应正确解标签的输出的自然对数,交叉熵误差的值是由正确解标签所对应的输出结果决定的
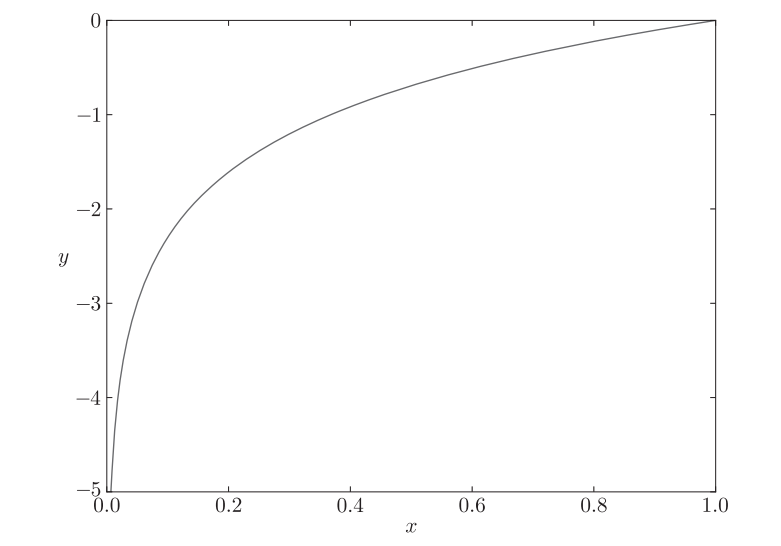
正确解标签对应的输出越大,交叉熵误差的值就越接近0,反之则越大,输出为1时,交叉熵误差为0,log函数图像如下
mini-batch学习
机器学习使用训练数据进行学习,其本质就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数,所以计算损失函数时必须将所有的训练数据作为对象
前面提到的损失函数都是针对的单个数据,若要求所有的训练数据的损失函数的总和,以交叉熵误差为例,损失函数可以写为:
$$
E = - \frac{1}{N} \sum_{n} \sum_{k} t_{nk} \log y_{nk}
$$这里是假设有$N$个数据,$t_{nk}$ 表示第 $n$ 个数据的第 $k$ 个元素的值,$t_{nk}$ 是监督数据,$t_{nk}$ 是神经网络的输出
通过除以 $N$ (正规化),可以求单个数据的平均损失函数,这样的平均化,可以获得和训练数据的数量无关的统一指标
如果将全部的训练数据作为对象求损失函数的总和,那这个计算过程会是非常漫长的,训练数据量非常庞大时,以全部训练数据作为对象计算损失函数更是不现实的
因此,从全部训练数据中选择一部分,作为全部训练数据的“近似”
神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习,用这一批数据的结果来近似全部数据的结果,这种学习方式就是所谓的 mini-batch学习
为什么要引入损失函数
为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值
损失函数的导数一般不会有0值,更不会恒为0(阶跃函数除外),而识别精度的导数恒为0或者只有极小部分不为0,这样权重的调整并不会影响其值,这并不是我们想要的
数值微分(数值梯度)
梯度法使用梯度的信息决定前进的方向
利用微小的差分求导数的过程就是所谓的数值微分(numerical differentiation)
基于数学式的推到求导数的过程,则称之为 解析性求解或解析性求导
梯度
由全部变量的偏导数汇总成的向量称为梯度
梯度法
寻找的最优参数是指损失函数取最小值时的参数
使用梯度来寻找损失函数最小值的方法就是所谓的 梯度法,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法
梯度表示的各点处的函数值减小最多的方向
函数最小值、极小值和鞍点处的梯度为 0(梯度法就是要找梯度为0的地方)
极小值是局部最小值,鞍点是从某个方向上看是极大值,从另一个方向看是极小值的点
学习高原:它是指,当函数很复杂且呈扁平状时,学习可能会进入一个(几乎)平坦的地区,陷入所谓的学习高原而无法前进的停滞期
根据寻找目的(最大值或最小值)的不同,梯度法分为了:梯度下降法和梯度上升法
通过反转损失函数的符号,求最小值和求最大值的问题可以变成相同的问题
神经网络(深度学习)中,梯度法一般是指的梯度下降法
学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数
在神经网络的学习中,一般会一边改变学习率的值,一边确认学习是否正确进行了
学习率这样的参数也被称为超参数,需要人工设定
神经网络的梯度
这里的梯度指的是损失函数关于权重参数的梯度
例子说明,一个神经网络的权重W形状为 2x3,损失函数用L表示,此时梯度可以用 $\frac{\partial L}{\partial W}$ 来表示,数学表示式如下
求出神经网络的梯度后,接下来只需根据梯度法,更新权重参数即可
学习算法的实现
神经网络的学习的步骤
前提是:神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为“学习”
(mini-batch)从训练数据中随机选出一部分数据,这部分数据称为mini-batch,目标是是减小mini-batch的损失函数的值
(计算梯度)为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度,梯度表示损失函数的值减小最多的方向
(更新参数)将权重参数沿梯度方向进行微小更新
(重复)重复前三步
因为更新权重参数采用的梯度法是梯度下降法,又是随机选择的mini-batch数据,所以称之为随机梯度下降法(stochastic gradient descent,SGD)
手写数字识别的神经网络的实现
基于测试数据的评价
神经网络的学习中,必须确认是否能够正确识别训练数据以外的其他数 据,即确认是否会发生过拟合
过拟合是指,虽然训练数据中的数字图像能被正确辨别,但是不在训练数据中的数字图像却无法被识别的现象
要评价神经网络的泛化能力,就必须使用不包含在训练数据中的数据,这就要用到测试数据了
另外又引入了一个新的概念——epoch
epoch是一个单位,一个epoch表示学习中所有训练数据均被使用过一次时的更新次数
如,对于10000笔训练数据,用大小为 100 笔数据的mini-batch进行学习时,重复随机梯度下降法 100次,所有的训练数据就都被“看过”了,此时,100次就是一个 epoch
遍历一次所有数据,就成为一个epoch
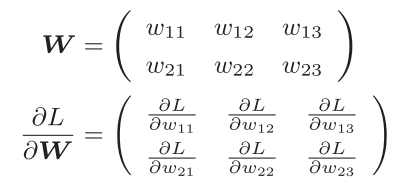
code
均方误差的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t)**2)
# 设2为正确解
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
result = mean_squared_error(y, t)
print(result)
y = np.array([0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0])
result_ = mean_squared_error(y, t)
print(result_)交叉熵误差的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
# 加上delta是为了避免出现 log(0),导致出现负无穷
delta = 1e-7
return -np.sum(t * np.log(y + delta))
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
result = cross_entropy_error(y, t)
print(result)
y = np.array([0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0])
result_ = cross_entropy_error(y, t)
print(result_)使用mini-batch学习的手写数字识别
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
sys.path.append(os.pardir) # 将父目录添加到系统路径,以便导入自定义模块
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.function import sigmoid, softmax
# 加载MNIST数据集
def get_data():
# normalize=True:将图像的像素值正规化到0.0~1.0
# flatten=True:将图像从2维数组转为1维数组
# one_hot_label=False:标签为0~9的数字,而不是one-hot编码
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
# 初始化神经网络
def init_network():
# 从文件加载预训练的网络参数(权重和偏置)
with open("sample_weight.pkl", rb)as f:
network = pickle.load(f)
return network
# 神经网络的预测函数
def predict(network, x):
# x 是输入数据
# 获取网络的权重和偏置
w1, w2, w3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 向前传播
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
batch_size = 100 # 设置批处理大小
accuracy_cnt = 0 # 初始化准确率计数器
# 使用批处理进行预测
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size] # 获取当前批次输入的数据
y_batch = predict(network, x_batch) # 对当前批次进行预测
p = np.argmax(y_batch, axis=1) # 获取每个样本预测概率最大的类别
accuracy_cnt += np.sum(p == t[i:i+batch_size]) # 统计预测正确的样本数
# 输出最终的识别准确率
print("Accuracy: " + str(float(accuracy_cnt) / len(x)))数值微分
导数的实现
2
3
h = 1e-4
return (f(h + x) - f(x)) / h上面这样计算函数f的差分是不准确的,它计算的是(x+h)和(x)之间的斜率,它与实际要计算的导数是有差异的,这一差异是因h不可能无限接近0导致的,这种属于是前向差分
正确的应该是 (x+h)和(x-h)之间的差分,以x为中心,这也称之为中心差分
2
3
h = 1e-4
return (f(x+h) - f(x-h)) / (2 * h)举个数值微分实例,y = 0.01X^2 + 0.1x
2
return 0.01*x**2 + 0.1 * x绘制其图像
2
3
4
5
6
7
8
9
import matplotlib.pylab as plt
x = np.arange(0.0, 20.0, 0.1)
y = fun_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.plot(x, y)
plt.show()计算x=5和x=10处的导数,并画出其图像(含切线)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
b = numerical_diff(fun_1, 10)
print(a)
print(b)
def tangent_line(f, x):
d = numerical_diff(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
x = np.arange(0.0, 20.0, 0.1)
y = fun_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
# 设置切点坐标
tangent_x = 5
tangent_y = fun_1(tangent_x)
# 绘制原函数和切线图像
tf = tangent_line(fun_1, tangent_x)
y2 = tf(x)
plt.plot(x, y)
plt.plot(x, y2)
# 绘制切点处辅助线
# 垂直x轴的
plt.axvline(x=tangent_x, color='gray', linestyle='--', alpha=0.5)
# 垂直y轴的
plt.axhline(y=tangent_y, color='gray', linestyle='--', alpha=0.5)
# 标记切点(红色圆点)
plt.plot(tangent_x, tangent_y, 'ro')
# 添加坐标标注
plt.text(tangent_x, tangent_y, f'({tangent_x:.1f}, {tangent_y:.2f})',
horizontalalignment='right', verticalalignment='bottom')
plt.show()
# 设置切点坐标
tangent_x = 10
tangent_y = fun_1(tangent_x)
tf = tangent_line(fun_1, tangent_x)
y3 = tf(x)
plt.plot(x, y)
plt.plot(x, y3)
# 绘制切点处辅助线
# 垂直x轴的
plt.axvline(x=tangent_x, color='gray', linestyle='--', alpha=0.5)
# 垂直y轴的
plt.axhline(y=tangent_y, color='gray', linestyle='--', alpha=0.5)
# 标记切点(红色圆点)
plt.plot(tangent_x, tangent_y, 'ro')
# 添加坐标标注
plt.text(tangent_x, tangent_y, f'({tangent_x:.1f}, {tangent_y:.2f})',
horizontalalignment='right', verticalalignment='bottom')
plt.show()偏导数
求 $f(x_0,x_1)=x_0^2+x_1^2$的偏导,并画出其函数图像
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 定义网格
x0 = np.linspace(-3, 3, 100)
x1 = np.linspace(-3, 3, 100)
X0, X1 = np.meshgrid(x0, x1)
# 定义函数
Z = X0**2 + X1**2
# 创建图形窗口
fig = plt.figure(figsize=(14, 6))
# 1. 三维图像
ax1 = fig.add_subplot(1, 2, 1, projection='3d')
ax1.plot_surface(X0, X1, Z, cmap='viridis', edgecolor='none')
ax1.set_title(r'$f(x_0, x_1) = x_0^2 + x_1^2$')
ax1.set_xlabel('$x_0$')
ax1.set_ylabel('$x_1$')
ax1.set_zlabel('$f(x_0, x_1)$')
# 2. 等高线图 + 梯度向量
ax2 = fig.add_subplot(1, 2, 2)
contour = ax2.contourf(X0, X1, Z, levels=30, cmap='viridis')
ax2.set_title('Contour and Gradient')
ax2.set_xlabel('$x_0$')
ax2.set_ylabel('$x_1$')
# 计算梯度(偏导)
grad_x0 = 2 * X0
grad_x1 = 2 * X1
# 绘制梯度向量(用 quiver 画箭头)
skip = 5 # 降低密度
ax2.quiver(X0[::skip, ::skip], X1[::skip, ::skip],
grad_x0[::skip, ::skip], grad_x1[::skip, ::skip],
color='white', alpha=0.8)
plt.colorbar(contour, ax=ax2, label='Function Value')
plt.tight_layout()
plt.show()梯度
简单的梯度的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def numerical_gradient(f, x):
h = 1e-4
# 生成和x形状相同的数组,且所有元素为0
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 还原值
return grad
print(numerical_gradient(fun_2, np.array([3.0, 4.0])))
print(numerical_gradient(fun_2, np.array([0.0, 2.0])))
print(numerical_gradient(fun_2, np.array([3.0, 0.0])))这里给出一个计算任意维数组的数值梯度
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
"""
计算任意维数组的数值梯度
参数:
f: 目标函数
x: 任意维度的数组
返回:
梯度数组,形状与x相同
实现原理:
1. 使用中心差分法计算梯度:(f(x+h) - f(x-h)) / (2h)
2. 对数组中的每个元素分别计算梯度
3. 使用numpy的迭代器处理任意维度的数组
"""
h = 1e-4 # 0.0001,微小的变化量
grad = np.zeros_like(x) # 创建与x形状相同的零数组,用于存储梯度
# 使用numpy的迭代器遍历数组的所有元素
# flags=['multi_index']: 获取多维索引
# op_flags=['readwrite']: 允许读写操作
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index # 获取当前元素的多维索引
tmp_val = x[idx] # 保存当前值
# 计算f(x+h)
x[idx] = tmp_val + h
fxh1 = f(x)
# 计算f(x-h)
x[idx] = tmp_val - h
fxh2 = f(x)
# 使用中心差分法计算梯度
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 恢复原始值
it.iternext() # 移动到下一个元素
return grad梯度下降法的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
init_x = np.array([-3.0, 4.0])
result_ = gradient_descent(fun_2, init_x=init_x, lr=0.1, step_num=100)
print(result_)图像展示梯度法的过程
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
x = init_x
x_history = []
for i in range(step_num):
x_history.append(x.copy())
grad = numerical_gradient(f, x)
x -= lr * grad
return x, np.array(x_history)
init_x = np.array([-3.0, 4.0])
lr = 0.1
step_num = 20
x, x_history = gradient_descent_(fun_2, init_x, lr, step_num)
plt.plot([-5, 5], [0, 0], '--b')
plt.plot([0, 0], [-5, 5], '--b')
plt.plot(x_history[:, 0], x_history[:, 1], 'o')
plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel("X0")
plt.ylabel("X1")
plt.show()神经网络的梯度
简单的神经网络
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 导入必要的库
import sys, os
# 将父目录添加到系统路径中,以便能够导入common模块
sys.path.append(os.pardir)
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class simpleNet:
"""
一个简单的神经网络类
实现了一个2输入3输出的单层神经网络
"""
def __init__(self):
# 初始化权重矩阵,使用随机数生成2x3的权重矩阵
self.W = np.random.randn(2,3)
def predict(self, x):
"""
前向传播函数
参数:
x: 输入数据
返回:
神经网络的输出
"""
return np.dot(x, self.W)
def loss(self, x, t):
"""
计算损失函数
参数:
x: 输入数据
t: 正确解标签
返回:
损失函数的值
"""
z = self.predict(x) # 获取神经网络的输出
y = softmax(z) # 使用softmax函数将输出转换为概率
loss = cross_entropy_error(y, t) # 计算交叉熵误差
return loss
# 创建测试数据
x = np.array([0.6, 0.9]) # 输入数据
t = np.array([0, 0, 1]) # 正确解标签
# 创建神经网络实例
net = simpleNet()
# 定义损失函数,用于计算梯度
f = lambda w: net.loss(x, t)
# 使用数值微分计算梯度
dW = numerical_gradient(f, net.W)
# 打印梯度结果
print(dW)这里需要注意的是,为什么要在类外定义一个损失函数f,因为类中的损失函数loss()是一个实例方法,需要访问实例的权重self.W,而numerical_gradient()函数参数中的f,需要的是一个纯函数,而不是一个类中的实例方法
手写数字识别的神经网络的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
import sys, os
sys.path.append(os.pardir) # 将父目录添加到系统路径中,以便导入common模块
from common.functions import *
from common.gradient import numerical_gradient
import numpy as np
class TwoLayerNet:
"""
两层神经网络类
实现了一个具有一个隐藏层的神经网络
结构:输入层 -> 隐藏层 -> 输出层
"""
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
"""
初始化神经网络
参数:
input_size: 输入层神经元数量
hidden_size: 隐藏层神经元数量
output_size: 输出层神经元数量
weight_init_std: 权重初始化的标准差
"""
# 初始化权重和偏置
self.params = {}
# 第一层权重矩阵,形状为(input_size, hidden_size)
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
# 第一层偏置,形状为(hidden_size,)
self.params['b1'] = np.zeros(hidden_size)
# 第二层权重矩阵,形状为(hidden_size, output_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
# 第二层偏置,形状为(output_size,)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
"""
前向传播,计算神经网络的输出
参数:
x: 输入数据
返回:
神经网络的输出(经过softmax后的概率分布)
"""
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
# 第一层计算
a1 = np.dot(x, W1) + b1 # 线性变换
z1 = sigmoid(a1) # 激活函数
# 第二层计算
a2 = np.dot(z1, W2) + b2 # 线性变换
y = softmax(a2) # 输出层激活函数
return y
def loss(self, x, t):
"""
计算损失函数
参数:
x: 输入数据
t: 正确解标签
返回:
损失函数的值
"""
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
"""
计算识别精度
参数:
x: 输入数据
t: 正确解标签
返回:
识别精度(0-1之间的值)
"""
y = self.predict(x)
y = np.argmax(y, axis=1) # 获取预测结果
t = np.argmax(t, axis=1) # 获取正确解
# 计算正确率
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
"""
使用数值微分计算梯度
参数:
x: 输入数据
t: 正确解标签
返回:
包含各层权重和偏置梯度的字典
"""
# 定义损失函数
loss_W = lambda W: self.loss(x, t)
# 计算各层参数的梯度
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1']) # 第一层权重梯度
grads['b1'] = numerical_gradient(loss_W, self.params['b1']) # 第一层偏置梯度
grads['W2'] = numerical_gradient(loss_W, self.params['W2']) # 第二层权重梯度
grads['b2'] = numerical_gradient(loss_W, self.params['b2']) # 第二层偏置梯度
return grads
def gradient(self, x, t):
"""
使用反向传播计算梯度
参数:
x: 输入数据
t: 正确解标签
返回:
包含各层权重和偏置梯度的字典
"""
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0] # 批次大小
# 前向传播
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# 反向传播
# 输出层的误差
dy = (y - t) / batch_num
# 第二层权重的梯度
grads['W2'] = np.dot(z1.T, dy)
# 第二层偏置的梯度
grads['b2'] = np.sum(dy, axis=0)
# 第一层的误差
dz1 = np.dot(dy, W2.T)
da1 = sigmoid_grad(a1) * dz1
# 第一层权重的梯度
grads['W1'] = np.dot(x.T, da1)
# 第一层偏置的梯度
grads['b1'] = np.sum(da1, axis=0)
return grads
net = TwoLayerNet(input_size=784, hidden_size=100, output_size=10)
print(net.params['W1'].shape)
print(net.params['b1'].shape)
print(net.params['W2'].shape)
print(net.params['b2'].shape)
x = np.random.rand(100, 784)
t = np.random.rand(100, 10)
grads = net.numerical_gradient(x, t)
print(grads['W1'].shape)
print(grads['b1'].shape)
print(grads['W2'].shape)
print(grads['b2'].shape)mini-batch的实现,以及基于测试数据的评价
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
import sys, os
sys.path.append('../../py_pro/DL/') # 将父目录添加到系统路径中,以便导入其他模块
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist # 导入MNIST数据集加载函数
from two_layer_net import TwoLayerNet # 导入两层神经网络类
# 加载MNIST数据集
# normalize=True: 将输入图像像素值正规化到0~1之间
# one_hot_label=True: 将标签转换为one-hot形式
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 创建两层神经网络实例
# 输入层784个神经元(28x28像素)
# 隐藏层50个神经元
# 输出层10个神经元(0-9十个数字)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
# 设置超参数
iters_num = 10000 # 训练迭代次数
train_size = x_train.shape[0] # 训练数据的大小
batch_size = 100 # 每批次的样本数
learning_rate = 0.1 # 学习率
# 用于记录训练过程的列表
train_loss_list = [] # 记录训练损失
train_acc_list = [] # 记录训练准确率
test_acc_list = [] # 记录测试准确率
# 计算每个epoch的迭代次数
iter_per_epoch = max(train_size / batch_size, 1)
# 开始训练
for i in range(iters_num):
# 随机选择批次数据
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
# 使用反向传播计算梯度(比数值微分更快)
#grad = network.numerical_gradient(x_batch, t_batch) # 数值微分(较慢)
grad = network.gradient(x_batch, t_batch) # 反向传播(较快)
# 更新参数
# 对每个参数进行梯度下降更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录训练损失
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 每个epoch计算一次训练集和测试集的准确率
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 绘制训练结果
markers = {'train': 'o', 'test': 's'} # 设置图例标记
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc') # 绘制训练准确率曲线
plt.plot(x, test_acc_list, label='test acc', linestyle='--') # 绘制测试准确率曲线
plt.xlabel("epochs") # x轴标签
plt.ylabel("accuracy") # y轴标签
plt.ylim(0, 1.0) # 设置y轴范围
plt.legend(loc='lower right') # 显示图例
plt.show() # 显示图形